分布式锁的实现方式
基于数据库实现分布式锁
可通过关系型数据库乐观锁和悲观锁来实现,还有一种方式是使用数据库的唯一索引,通过对唯一key分片,也可以有很优秀的吞吐
通过乐观锁实现
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。那么我们如何实现乐观锁呢,一般来说有以下2种方式:
-
使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
-
乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
-- 线程1查询,当前left_count为1,则有记录,当前版本号为1234
select left_count, version from t_bonus where id = 10001 and left_count > 0
-- 线程2查询,当前left_count为1,有记录,当前版本号为1234
select left_count, version from t_bonus where id = 10001 and left_count > 0
-- 线程1,更新完成后当前的version为1235,update状态为1,更新成功
update t_bonus set version = 1235, left_count = left_count-1 where id = 10001 and version = 1234
-- 线程2,更新由于当前的version为1235,udpate状态为0,更新失败,再针对相关业务做异常处理
update t_bonus set version = 1235, left_count = left_count-1 where id = 10001 and version = 1234
数据库乐观锁类似于各种语言和cpu原子指令中的CAS操作,不通过加锁来实现并发控制
通过悲观锁实现
通过悲观锁来实现分布式锁相对于简单,通过粗暴的数据库加锁来实现,根据不同的数据库、存储引擎可实现表锁、页锁、行锁,通过它们可实现性能不同的。可利用数据库共享锁来实现读锁,排它锁来实现写锁。
-
在oracle数据库中,可使用以下语句打开表锁。 LOCK TABLE 表 IN EXCLUSIVE MODE; 加锁后其它人不可操作,直到加锁用户解锁,用commit或rollback解锁。
-
页锁是某些数据库支持,如mysql的innodb引擎25个行锁直接升级为页锁。
-
基于MySQL的InnoDB引擎,可以使用以下方法来实现加锁操作:
public boolean lock(){
Connection.setAutoCommit(false);
while (true) {
try {
result = select * from MethodLock where methodName = 'xxxx' for update;
if (result == null) {
return false;
}
} catch (Exception e) {
}
sleep(1000);
}
returnType false;
}
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
public void unlock(){
connection.commit();
}
通过connection.commit()操作来释放锁。
使用redis实现分布式锁
- 选用Redis实现分布式锁原因:
- Redis有很高的性能;
- Redis命令对此支持较好,实现起来比较方便
- 使用命令介绍:
# SETNX
SETNX key val # 当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。1
# expire
expire key timeout # 为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。1
# delete
delete key # 删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。 3. 实现思想:
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
问题: 不加过期时间会潜在死锁
- 不能保证释放锁
存在一个问题,就是如果加锁和解锁中间执行的业务中断,比如服务器挂了,或者线程被杀掉,那么就可能会导致 del 指令没有被调用,这样就会陷入死锁,锁永远得不到释放
- 操作非原子性
由于 setnx 和 expire 非原子性,如果在 setnx 和 expire 之间出现机器挂掉或者是被人为杀掉,就会导致死锁。
不能解决超时问题 考虑如下场景,加锁和解锁之间的业务非常耗时,那么就可能存在:
- 线程一拿到锁之后执行业务
- 还没执行完锁就超时过期了
- 线程二此时拿到锁乘虚而入,开始执行业务…
当然这是redis分布式锁在死锁和超时问题之间做出的妥协,没办法完全避免,但是需要业务在使用时,衡量加锁的粒度及过期时间 超时问题,Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。 因为这时候锁过期了,第二个线程重新持有了这把锁,但是紧接着第一个线程执行完了业务逻辑,就把锁给释放了,第三个线程就会在第二个线程逻辑执行完之间拿到了锁。
基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
利用节点名称的唯一性来实现独占锁
ZooKeeper机制规定同一个目录下只能有一个唯一的文件名,zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建/lock/${lock_name}_lock节点,最终成功创建的那个客户端也即拥有了这把锁,创建失败的可以选择监听继续等待,还是放弃抛出异常实现独占锁。
利用临时顺序节点控制时序实现
(1)创建一个目录mylock; (2)线程A想获取锁就在mylock目录下创建临时顺序节点; (3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁; (4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点; (5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式
当然,zk的API接口中创建节点、删除节点、监听的操作都是原子的。
redis官方解决方案 RedLock
- https://redis.io/topics/distlock 集群环境如何保证锁的安全,Redlock 算法就是为了解决这个问题,他的原理是在加锁时,向过半节点发送 set 指令,只要过半节点返回成功,那就认为加锁成功。释放锁时,再向所有节点发送 del 指令。
代价也很明显,跟tomcat 的 session 共享机制一样,随着集群机器的增加,势必会有损性能。Redlock 算法还需要考虑出错重试、时钟漂移等很多细节问题。
所以一般这种由于主从节点同步时间差导致的锁不安全问题,业务系统一般都是选择忍受的,生产上这种场景发生的概率也不大。
How to do distributed locking
我们要锁来干啥呢?两个原因:
- 提升效率,用锁来保证一个任务没有必要被执行两次。比如(很昂贵的计算)
- 保证正确,使用锁来保证任务按照正常的步骤执行,防止两个节点同时操作一份数据,造成文件冲突,数据丢失
RedLock问题:
- RedLock 只是保证了锁的高可用性,并没有保证锁的正确性
- RedLock 是一个严重依赖系统时钟的分布式系统
对于提升效率的场景下,RedLock 太重。 对于对正确性要求极高的场景下,RedLock 并不能保证正确性。
有一种解决方案是增加fencing token来解决多客户端写入的问题,fencing token的生成要高效且满足consensus
Making the lock safe with fencing
The fix for this problem is actually pretty simple: you need to include a fencing token with every write request to the storage service. In this context, a fencing token is simply a number that increases (e.g. incremented by the lock service) every time a client acquires the lock. This is illustrated in the following diagram:
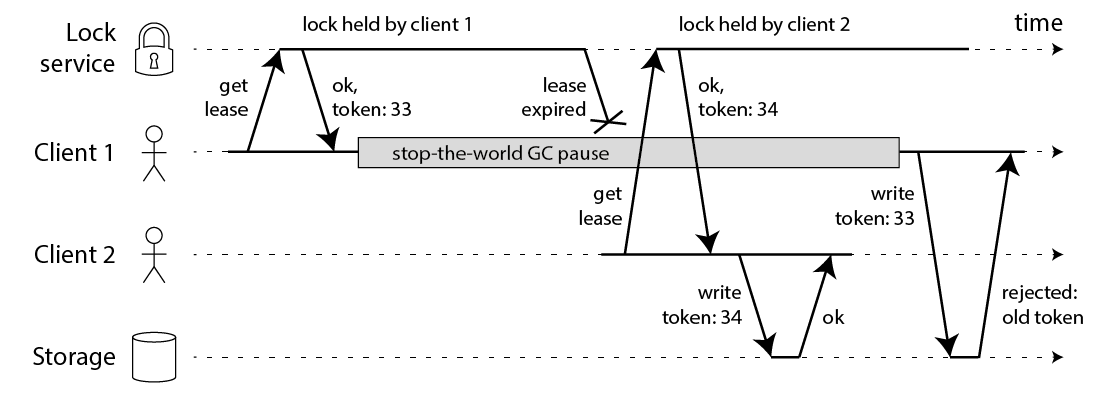
Using fencing tokens to make resource access safe
Client 1 acquires the lease and gets a token of 33, but then it goes into a long pause and the lease expires. Client 2 acquires the lease, gets a token of 34 (the number always increases), and then sends its write to the storage service, including the token of 34. Later, client 1 comes back to life and sends its write to the storage service, including its token value 33. However, the storage server remembers that it has already processed a write with a higher token number (34), and so it rejects the request with token 33.
Note this requires the storage server to take an active role in checking tokens, and rejecting any writes on which the token has gone backwards. But this is not particularly hard, once you know the trick. And provided that the lock service generates strictly monotonically increasing tokens, this makes the lock safe. For example, if you are using ZooKeeper as lock service, you can use the zxid or the znode version number as fencing token, and you’re in good shape [3].
However, this leads us to the first big problem with Redlock: it does not have any facility for generating fencing tokens. The algorithm does not produce any number that is guaranteed to increase every time a client acquires a lock. This means that even if the algorithm were otherwise perfect, it would not be safe to use, because you cannot prevent the race condition between clients in the case where one client is paused or its packets are delayed.
And it’s not obvious to me how one would change the Redlock algorithm to start generating fencing tokens. The unique random value it uses does not provide the required monotonicity. Simply keeping a counter on one Redis node would not be sufficient, because that node may fail. Keeping counters on several nodes would mean they would go out of sync. It’s likely that you would need a consensus algorithm just to generate the fencing tokens. (If only incrementing a counter was simple.)